
Caveman: El truco para recortar el 65% de tokens al hablar con la IA
En ComandoIT estamos obsesionados con la eficiencia.
Si estás metido en el desarrollo asistido por IA (como Claude Code o GitHub Copilot), sabes que hay dos grandes cuellos de botella: la latencia y el coste de los tokens.
Cada palabra extra que escribes es dinero y tiempo desperdiciados.
Por eso, hoy os traemos una joya minimalista descubierta en GitHub que sigue la filosofía del «menos es más»: caveman.
El problema del «Prompt Enginnering» verboso
A menudo nos enseñan que para obtener buenos resultados de una IA, debemos ser extremadamente detallados, usar un lenguaje formal y construir oraciones perfectas. Esto está bien para el chat general, pero cuando estás en la terminal, picando código y depurando errores, necesitas velocidad.
Escribir: «Por favor, Claude, analiza este archivo de configuración y genera una lista de los puertos que están abiertos, pero excluye el puerto 80 si es posible», consume tokens innecesarios tanto en tu prompt (entrada) como en el procesamiento de la IA.
¿Qué es Caveman?
caveman es una skill (habilidad) de código abierto para Claude Code, desarrollada por Julius Brussee.
Su concepto es tan simple que roza lo genial.
No es un algoritmo complejo de compresión; es una instrucción táctica que obliga a la IA a comunicarse de la forma más directa posible.
El Principio:
La premisa central es literal: «why use many token when few token do trick» (¿por qué usar muchos tokens cuando pocos tokens hacen el truco?).
O como diría un hombre de las cavernas: «No hablar mucho. Decir esencial.«
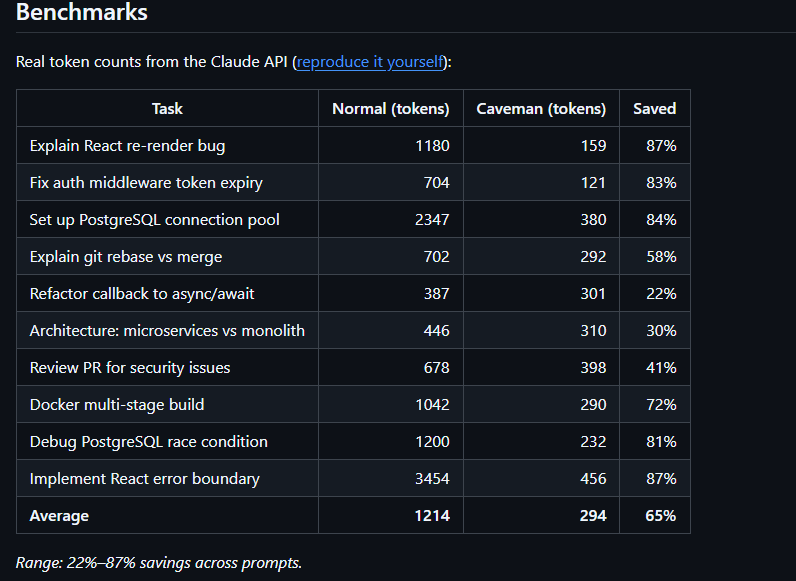
No estamos aquí por la anécdota divertida. Caveman ofrece beneficios reales en producción:
- Recorte de Tokens del 65%: No es una cifra pequeña. Al eliminar preposiciones, artículos y formalidades, reduces drásticamente la cantidad de datos que viajan de ida y vuelta a la API.
- Ahorro de Costes: Si pagas por token (lo cual es estándar), estás reduciendo tus costes de API en más de la mitad en cada interacción. En despliegues grandes o en CI/CD asíncrono, esto es vital.
- Reducción de Latencia: Menos tokens significan respuestas más rápidas. La IA no tiene que procesar sintaxis compleja para entender tu intención.
- Claridad Operativa: Al forzar la comunicación directa, hay menos espacio para la ambigüedad operativa. La IA se centra en el «hacer» y no en el «adornar«.
El «Caveman» en Acción: De Poeta a Neandertal de la Terminal
Vamos a ver cómo pasamos de redactar una tesis doctoral a simplemente gruñirle a la IA para que trabaje.
Situación: Tu servidor se está arrastrando como un zombi en lunes por la mañana. Sospechas del archivo server.js.
El Enfoque «Me sobra el dinero y el tiempo» (Sintaxis Estándar):
«Querido Claude, espero que estés teniendo un día fantástico. Verás, tengo una pequeña inquietud operativa. He estado observando el rendimiento de mi aplicación y tengo la ligera sospecha de que el bucle principal dentro del archivo server.js podría estar experimentando un comportamiento anómalo, posiblemente un ‘memory leak’. ¿Serías tan amable de analizarlo con detenimiento y, si no es mucha molestia, sugerir una contramedida optimizada para restablecer la paz en mi entorno de producción? Quedo a la espera de tus gratas noticias. Un saludo cordial.»
El Enfoque ComandoIT «Tengo 5 minutos antes del deploy» (Sintaxis Caveman):
«Review server.js bucle leak. Solución rápida.»
La Respuesta de la IA (Que también es Caveman y no se ofende):
Lejos de pedirte que moderes tu lenguaje, la IA (que también prefiere ahorrar tokens para el fin de semana) te responderá en el mismo dialecto:
“Encontrar leak. Bucle infinito. Usar forEach no, usar for...of. Parchear aquí. Usar esto:”
Resultado bueno: Mismo código, mismo fix, pero te has ahorrado 150 tokens de cortesía y 2 minutos de tu vida redactando correos innecesarios a una máquina.
Cómo Implementar el Modo «Hombre de las Cavernas»
Aunque el proyecto original se enfoca como una skill para Claude Code, el principio es universal.
Si usas la terminal, puedes crear un alias de prompt o una variable de entorno que anteponga la instrucción de sistema. O mejor aún, puedes configurar tu prompt de sistema global en tus scripts de automatización:
SYSTEM_PROMPT="Actuar como 'caveman'. No hablar mucho. Decir esencial. Solo tokens útiles. Ignorar modales. Decir rápido."
A partir de ahí, cualquier consulta que le hagas se procesará bajo esta directiva de optimización agresiva.